Scrapy生产部署
大家对于scrapy的管理主要倾向于在写scrapy上,但是很多人没有去控制如何对scrapy进行部署和使用。使用scrapyd可以很好地对各种爬虫进行管理。如果加上scrapyd-web就能更好的对爬虫进行控制和可视化。下面就分别的记录两个爬虫的使用和配置。
scrapyd的安装和使用
scrapyd分为两个端,服务器端安装scrapyd,客户端安装scrapyd-client。然后在客户端进行爬虫的编写,完成后发布到服务器端即可。
1. 服务器端scrapyd的安装和使用
服务器端的scrapyd的安装可以在virtualenv下使用。
新建virtualenv的环境,然后使用pip安装 scrapyd即可。
#记得要安装Twisted,否则的话后面使用client部署会报错
pip3 install Twisted==18.9.0
pip3 install scrapyd报错 <span>builtins.AttributeError</span>: <span>'int' object has no attribute 'splitlines'</span> 如果看到这个报错就说明需要安装Twisted
安装好之后,在venv环境下面执行 scrapyd就可以启动。但是这里注意需要修改几个配置
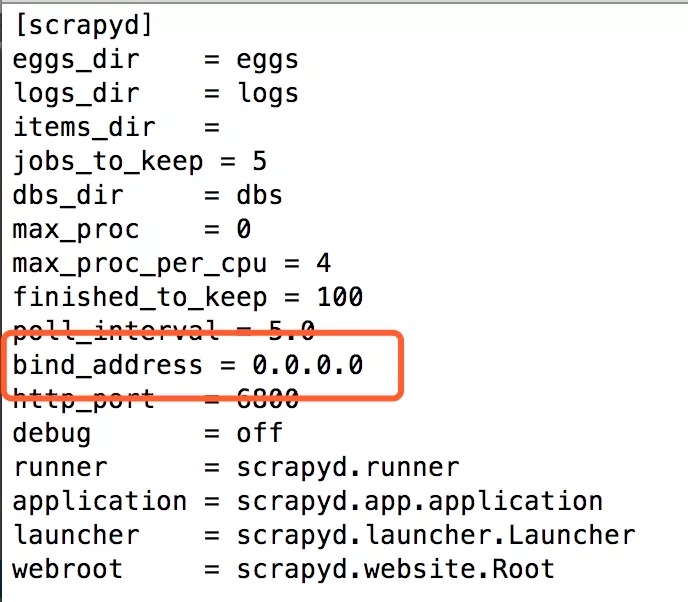
搜索default_scrapyd.conf文件,在venv目录下。然后修改bind_address 到0.0.0.0,这样才能保证外部输入
也可以在服务器端使用命令后台来开启scrapyd进程
2. 安装scrapy-client端
在本地安装scrapy-client ,pip isntall scrapy-client
安装完成后,在自己的scrapy工程目录下,执行
会生成一个scrapy.cfg文件。修改成如下配置
完成之后就可以发布到服务器端了
可以在浏览器端查询爬虫的情况
http://121.41.8.92:6800/jobs
在日志中可以查看到爬虫的运行情况 http://121.41.8.92:6800/logs
配置生产环境的scrapyd
在生产环境上如果直接开启6800端口,那么任何人都可以到你的服务器上面发布scrapy任务了,这样肯定没有安全性保障,所以需要配置相应的nginx鉴权来保证用户鉴权
安装sudo apt-get install apache2-utils
配置 nginx.conf
重载nginx service nginx reload
注意这里需要修改非6800端口,否则两个端口就冲突了。
修改scrapy的配置文件 venv/lib/python3.6/site-packages/scrapyd/default_scrapyd.conf
记得这里一定要修改为127.0.0.1,这样就可以放置外网的访问scrapyd,而只能通过nginx进行访问了。
配置完成后重启scrapyd就可以生效了。再次访问的时候就可以
最后重新配置scrapydweb。
scrapyd可以配置成公网的,方便外部访问
配置的时候最后使用第三个元组的形式将配置项导入。然后访问的时候即可使用
scrapydweb的使用
基本配置
scrapydweb 的配置文件中有许多需要配置的内容,安装完成后scrapydweb会自动的将配置文件拷贝到项目目录。可以通过查看
安装完成后会在项目目录下自动配置scrapydweb_settings_v8.py文件
配置nginx解析
完成后即可实现远程登录
远程发布及使用
scrapydweb支持多种远程提交到远程服务器
最简单的方法还是直接在本地scrapy项目的地方使用命令行进行上传
每次deploy之后在服务器端会有一个版本信号,在后面调用的时候可以针对这个版本进行run
待完成部分
参考blog
【Python实战】用Scrapyd把Scrapy爬虫一步一步部署到腾讯云上,有彩蛋 python – 我们如何配置scrapyd以将virtualenv用于项目? 如何在Ubuntu上通过Nginx设置HTTP认证 scrapyd和scrapyd-client使用教程 使用Scrapyd部署爬虫 官方教程平台 scrapydweb-github项目 scrapyd官方说明文档
Last updated