ieltsonlinetest雅思练习题
入口页面: https://ieltsonlinetests.com/ielts-exam-library#academic
Test Collection: 入口页面academic下面的每一个是一个TestCollection
例如,第一个https://ieltsonlinetests.com/collection/ielts-recent-actual-test-answers-vol-6
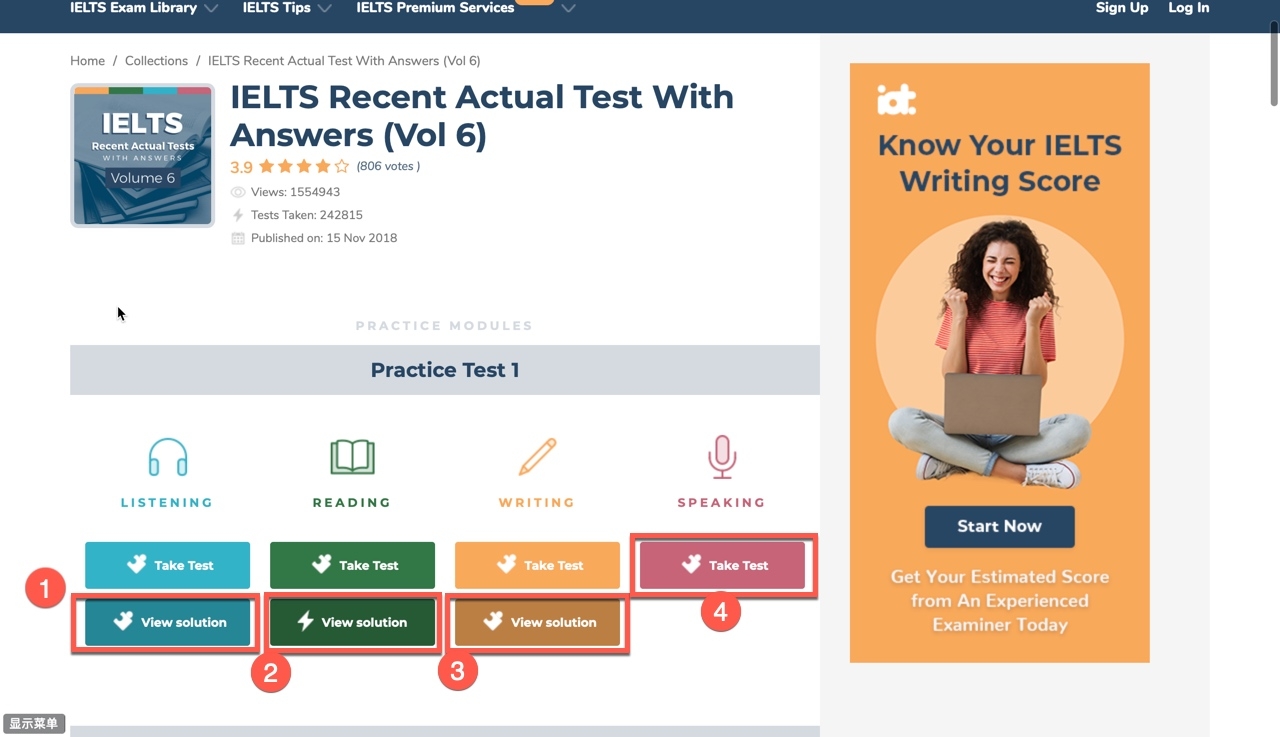
每一个TestCollection下会包含多个Practice Test。 每个Practice Test 又包含Listening、Reading、Writing、Speaking四个部分。其中Listening、Reading、Writing三个部分我们需要View Solution部分,Speaking部分我们需要Take Task部分。
每个抓取的页面需要存储页面内容到文件目录,**.html ,并在数据库中记录 url、文件路径
说明:
每个page代表一个抓取页,需要把每个抓取页存储
url : 记录抓取页面的url链接 filename: 存储的文件名,记录在数据库中 path:存储的位置,记录在数据库中
ielts考试item模块对应
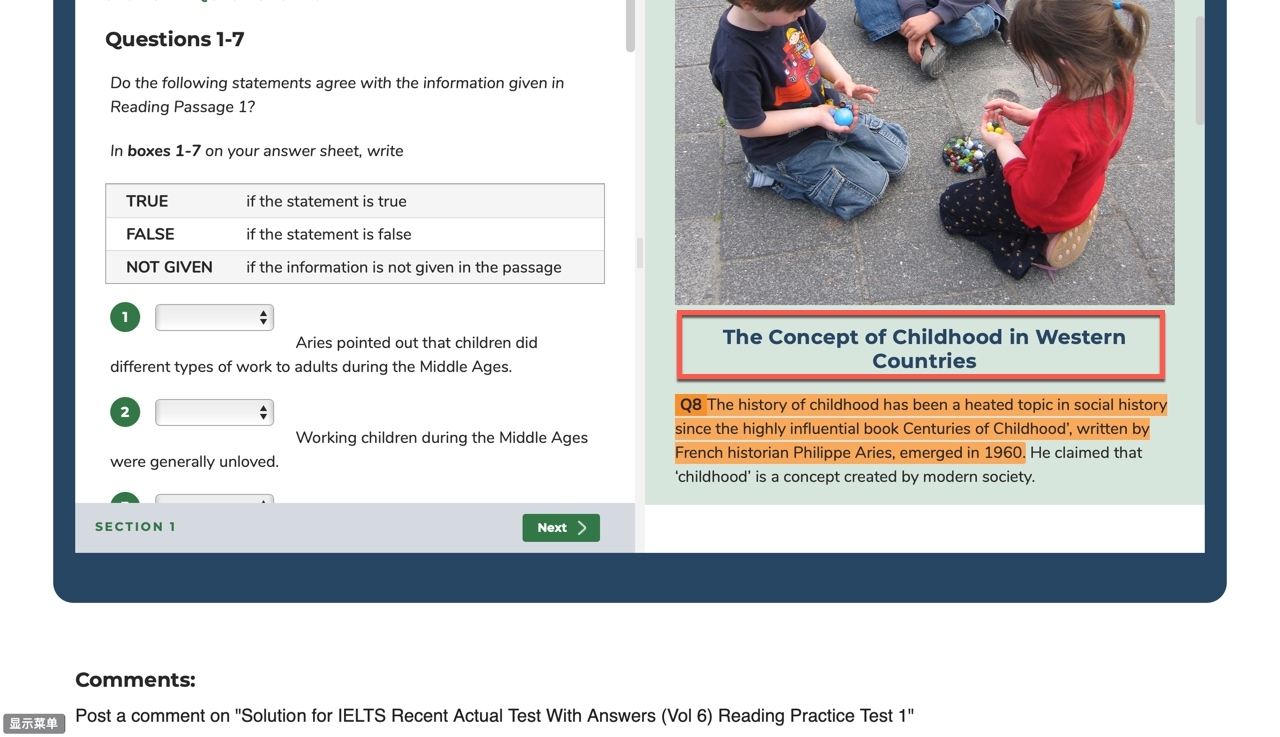
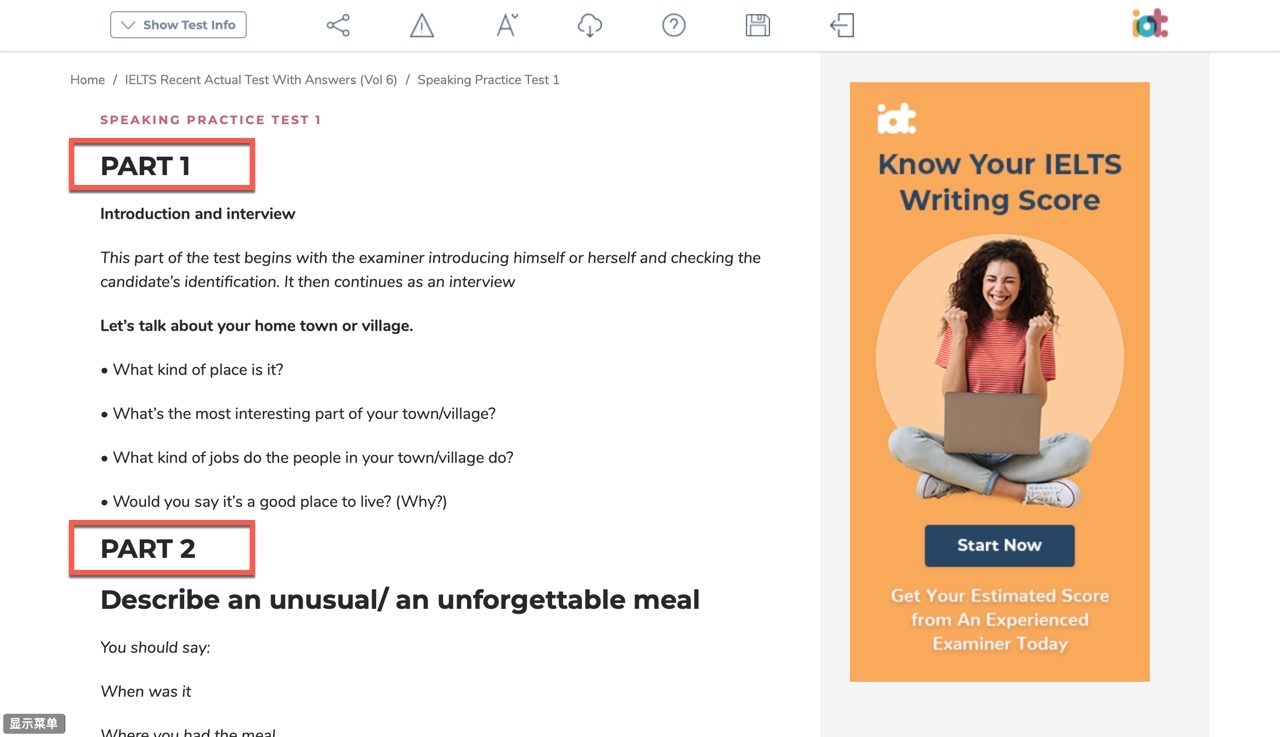
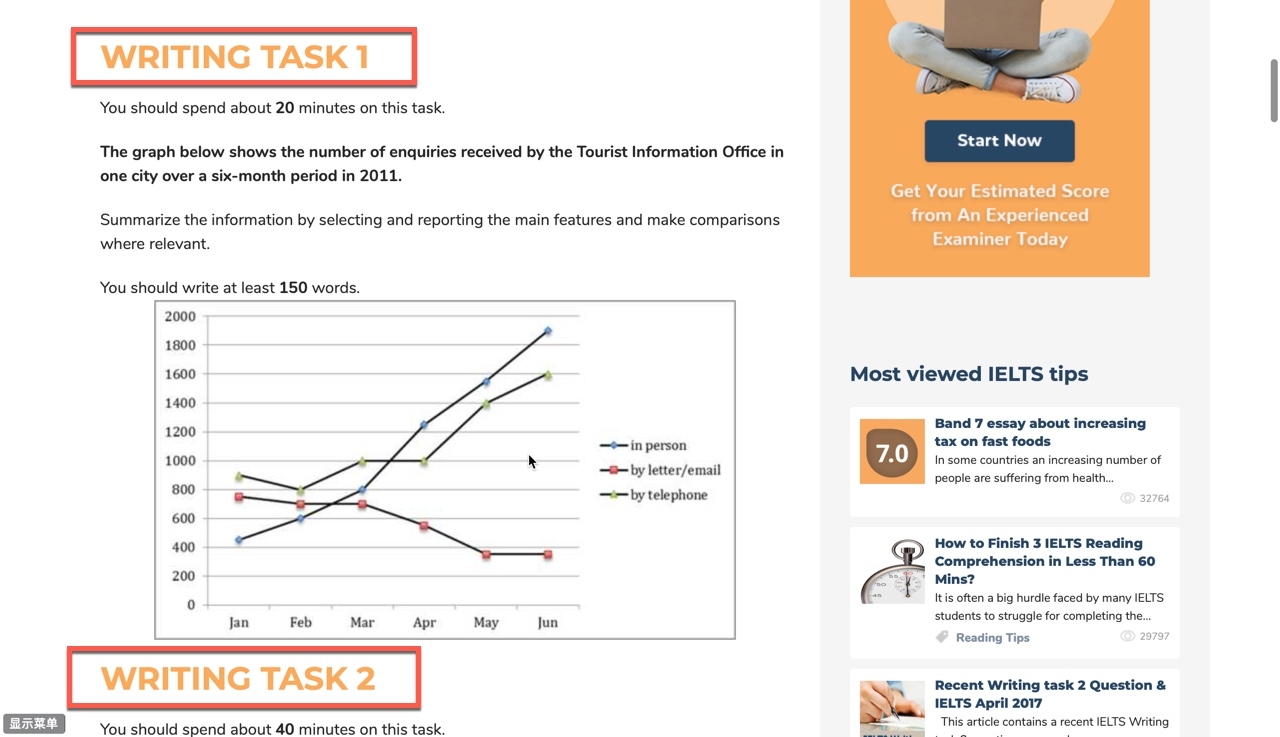
item:一篇Reading文章对应一个item, 一篇Listening文章对应一个item (mp3可能是包含三个的),一个Writing对应一个(分小作为和大作文),一个part一个item。
collection_name:对应每一个练习。 例如:IELTS Recent Actual Test With Answers (Vol 6) 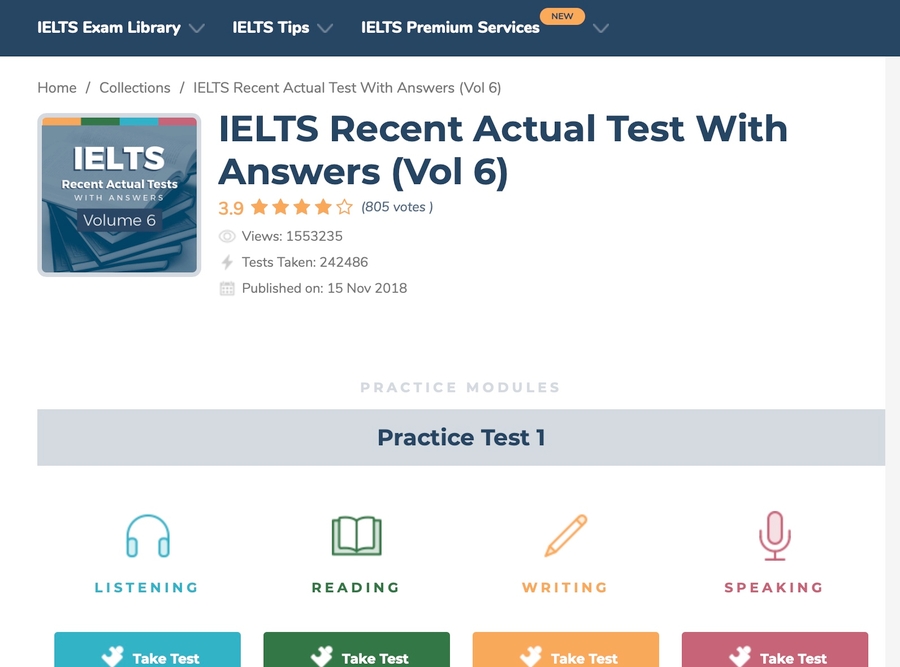
practice_name: 对应每一个练习,例如 Practice Test 1 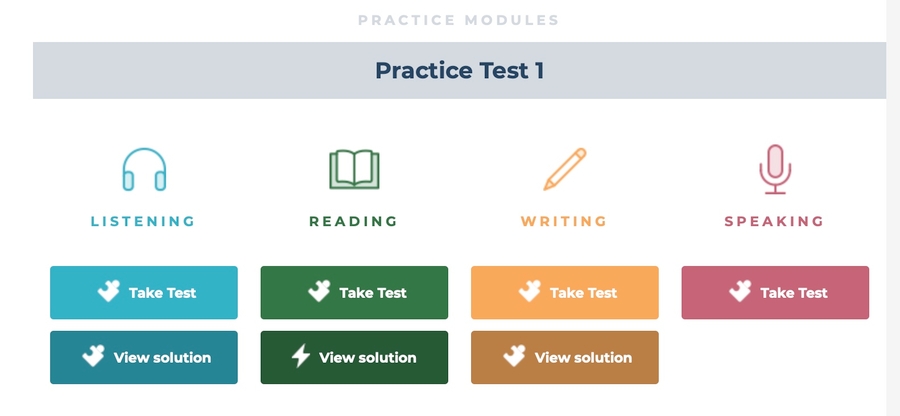
url: 对应一个collection的url地址,例如 https://ieltsonlinetests.com/collection/ielts-recent-actual-test-answers-vol-6
type: Listening\Reading\Writing\Speaking 四种类型
article: 阅读、听力的文章记录在这里,这里只记录文章内容,不记录格式
article_html:阅读、听力的文章记录在这里,这里记录整体的HTML
question: 预留,保持为空。现在不好解析。 后面可以尝试这里怎么写
question_html: 阅读的问题、听力的问题、写作的题目、口语的题目
answer:
answer_html: 答案的HTML格式
title: 阅读文章的标题
order: 阅读、听力文章的顺序。单篇的存储方式可以使用。
sub_type: 子类型,写作分为大作文、小作文。口语分为part1,2,3
parse中解析每一个item的url链接,获取所有的acdemic的地址。注意这里是相对地址,需要一个base_url进行绑定。使用yield scrapy.Request()进行转发。如使用parse_collection 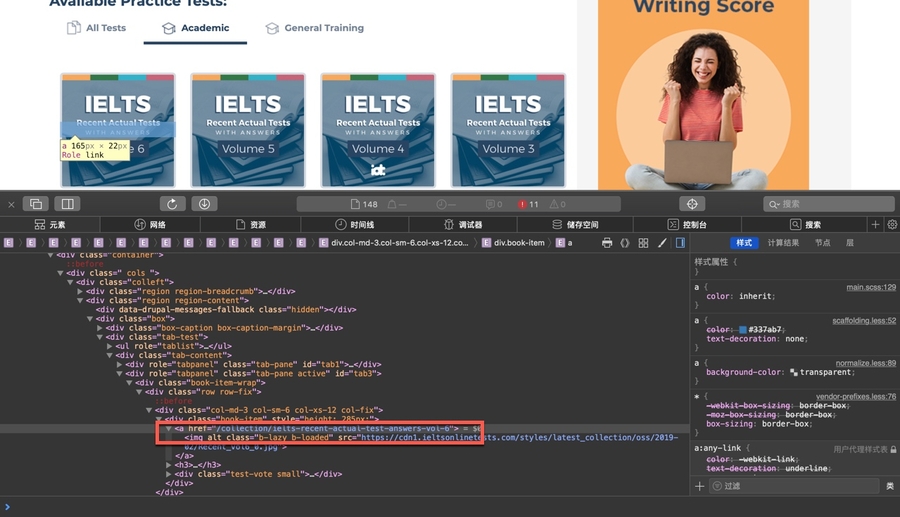
parse_collection解析,分别解析4个链接,每个链接都应该是一个list,是同类型的文章链接。同时分别yield scrapy.Requst到四个不同类型的解析方法中去。比如起名 parse_reading,parse_listening,parse_writing,parse_speaking。将不同的链接进入不同的解析包
定义item,在四个解析中分别将解析的内容写入item。
在pipeline中存储HTML文件,在讲page和item写入数据库。
这样就能获取ielts_online上的所有考试内容。
将阅读的article写成txt,可以方便我们做词频分析