zhan项目
zhan.com雅思练习题
zhan
输入
入口查找
入口页面: http://top.zhan.com/ielts/
二级链接页面
听力链接: $x('//*[@id="hm_header"]//a[@title="雅思听力"]/@href') call_back: yelts_listen 阅读链接: $x('//*[@id="hm_header"]//a[@title="雅思阅读"]/@href') call_back: yelts_read 写作链接: $x('//*[@id="hm_header"]//a[@title="雅思写作"]/@href') call_back: yelts_write 口语链接: $x('//*[@id="hm_header"]//a[@title="雅思口语"]/@href') call_back: yelts_speak
collection页面
听力collection : $x('//ul[@class="tpo_list tpo_no_row"]/li/a/@href') 阅读collection : $x('//ul[@class="tpo_list tpo_no_row"]/li/a/@href') 写作collection : $x('//ul[@class="tpo_list tpo_no_row"]/li/a/@href') 口语collection : $x('//ul[@class="tpo_list tpo_no_row"]/li/a/@href')
这些是同样的,是否可以考虑使用方法来写?
pratice
听力: $x('//div[@class="item_img"]//a[contains(string(.), "回顾")]/@href') $x('//div[@class="tpo_desc_item"]//a[contains(string(.), "回顾")]/@href')
阅读:$x('//div[@class="item_img"]//a[contains(string(.), "回顾")]/@href') $x('//div[@class="tpo_desc_item"]//a[contains(string(.), "回顾")]/@href')
写作:$x('//div[@class="tpo_talking_item"]//a[contains(string(.), "回顾")]/@href')
口语:$x('//div[@class="tpo_talking_item"]//a[contains(string(.), "回顾")]/@href')
从入口页面进入二级链接页面,然后从二级目录页面(包含听力、阅读、口语、写作四个部分),然后在每个部分分别进入到Collection页面中,可以获取4-12共9本书的内容。然后我们分别针对9本collection分别进入到下面的每一个pratice中去,后续就是针对每个pratice的每一个page。
输出
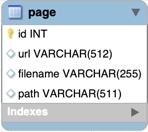
page存储
每个抓取的页面需要存储页面内容到文件目录,**.html ,并在数据库中记录 url、文件路径
说明:
每个page代表一个抓取页,需要把每个抓取页存储
url : 记录抓取页面的url链接 filename: 存储的文件名,记录在数据库中 path:存储的位置,记录在数据库中
ielts考试item模块对应
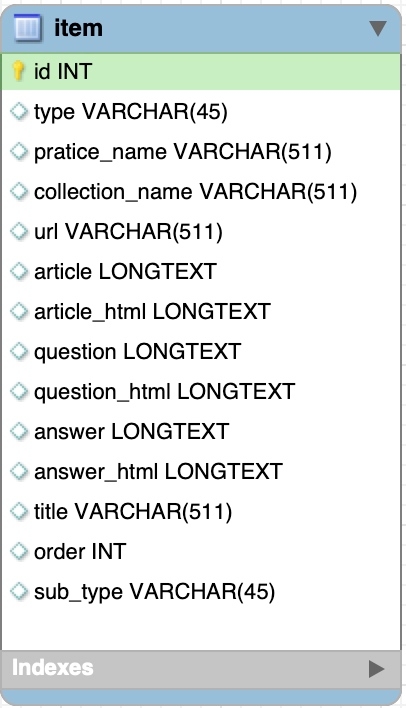
item:一篇Reading文章对应一个item, 一篇Listening文章对应一个item (mp3可能是包含三个的),一个Writing对应一个(分小作为和大作文),一个part一个item。
collection_name:对应每一个练习。
听力: $x('//*[@id="crumbs"]/a[4]/text()') 阅读: $x('//*[@id="crumbs"]/a[4]/text()') 口语: $x('//*[@id="crumbs"]/a[4]/text()') 写作: $x('//*[@id="crumbs"]/a[4]/text()')
practice_name: 对应每一个练习,例如 Practice Test 1
听力:$x('//*[@id="crumbs"]/a[5]/h1/text()') 阅读:$x('//*[@id="crumbs"]/a[5]/h1/text()') 口语:$x('//*[@id="crumbs"]/a[5]/h1/text()') 写作:$x('//*[@id="crumbs"]/a[5]/h1/text()')
url: 对应一个collection的url地址,例如 https://ieltsonlinetests.com/collection/ielts-recent-actual-test-answers-vol-6
type: Listening\Reading\Writing\Speaking 四种类型
从call_back方法中可以指定
article: 阅读、听力的文章记录在这里,这里只记录文章内容,不记录格式
听力: $x('//p[@class="article"]') 阅读: $x('//div[@class="drag_area_left_noimg canDoDrag pull-left"]')
article_html:阅读、听力的文章记录在这里,这里记录整体的HTML
听力: $x('//p[@class="article"]') 阅读: $x('//div[@class="drag_area_left_noimg canDoDrag pull-left"]')
question: 预留,保持为空。现在不好解析。 后面可以尝试这里怎么写
口语:$x('//div[@class="talk_title"]') $x('//div[@class="ielts_talking_desc"]') 写作: $x('//div[@class="ielts_listen_review_scroll nano customize-style-scroll has-scrollbar"]')
question_html: 阅读的问题、听力的问题、写作的题目、口语的题目
听力: $x('//div[@class="question"]') 阅读: $x('//div[@class="question"]') 口语:$x('//div[@class="talk_title"]') $x('//div[@class="ielts_talking_desc"]') 写作: $x('//div[@class="ielts_listen_review_scroll nano customize-style-scroll has-scrollbar"]')
answer:
口语:$x('//*[@id="jp_audio_0"]/@src') (mp3)
answer_html: 答案的HTML格式
title: 阅读文章的标题
听力: $x('//span[@class="article_title"]/text()') 阅读: $x('//span[@class="article_title"]/text()')
order: 阅读、听力文章的顺序。单篇的存储方式可以使用。
$x('/html/head/title/text()')
sub_type: 子类型,写作分为大作文、小作文。口语分为part1,2,3
$x('/html/head/title/text()')
mp3:
听力://*[@id="jp_audio_0"/@src]
实现流程
Last updated